
Written by: Anish Rao, Head of Growth, Listen Labs | Last updated: March 29, 2026
Key Takeaways
- Startups with low traffic see strong results with PostHog and Statsig, thanks to generous free tiers and sequential testing.
- Open-source options like GrowthBook support warehouse-native experiments while avoiding vendor lock-in and extra data copies.
- Data-mature teams gain from Eppo and Statsig’s advanced stats, including CUPED and SRM detection, directly in Snowflake or BigQuery.
- Enterprises often choose full-stack platforms like Optimizely for governance, while Amplitude Experiment stands out for analytics-driven targeting.
- Pair A/B tests with Listen Labs’ qual-at-scale insights and book a demo to uncover the “why” behind your results in under 24 hours.
Startup-Friendly A/B Testing: PostHog and Statsig
Early-stage SaaS companies need A/B testing tools that handle limited traffic and still support future growth. PostHog offers a generous free tier up to 1 million events per month, combining product analytics, session recordings, and feature flags in a single platform. Its open-source foundation prevents vendor lock-in, and the developer-first approach fits engineering-heavy teams.
Statsig stands out for startups with its free tier up to 500 million events per year and sequential statistical engine that delivers faster results with smaller sample sizes. This mix of generous limits and efficient stats lets young teams run serious experiments without waiting months for significance. Built by ex-Facebook engineers, Statsig provides enterprise-grade capabilities including the Pulse statistical engine and unlimited feature flags. Statsig costs 50-80% less than LaunchDarkly at scale, which helps growing teams preserve runway while they build experimentation muscle.
Free and Open-Source Control: GrowthBook and PostHog
Beyond generous free tiers, some teams prioritize full infrastructure control and strict data ownership. Open-source A/B testing platforms eliminate vendor lock-in while giving complete control over data and infrastructure. GrowthBook connects directly to data warehouses like Snowflake, BigQuery, or Redshift, enabling warehouse-native testing without data duplication. Its self-hosted option supports unlimited experiments, users, and traffic at zero software cost.
PostHog’s open-source model adds self-hosting alongside its cloud offering, building on the generous free tier mentioned earlier. The platform combines A/B testing with comprehensive product analytics, so product teams work from a single source of truth. Both platforms support Bayesian and Frequentist statistical engines, which gives flexibility for different experimental philosophies.
Analytics-Driven Experimentation: Amplitude Experiment
Teams already using Amplitude Analytics gain clear advantages with Amplitude Experiment’s integrated workflow. The platform enables behavioral targeting based on Amplitude Analytics cohorts, so experiments reach users based on real actions instead of simple demographics.
Amplitude Experiment includes CUPED variance reduction and sequential testing, which improves statistical power and shortens test duration. The unified workflow keeps metrics consistent across analytics and experimentation, avoiding the data discrepancies that appear in multi-tool stacks. Discover how Listen Labs adds qualitative depth to your Amplitude behavioral data and see the integration in action.
Feature Flag Powerhouse for Engineers: LaunchDarkly
While Amplitude Experiment serves analytics-driven product teams, engineering-focused organizations often start with feature management as the primary need. LaunchDarkly pioneered feature flag management and remains a leading choice for engineering teams managing complex feature releases. The platform provides enterprise-grade feature flags with percentage rollouts, real-time kill switches, and granular user targeting. Its SDKs support every major programming language and framework.
LaunchDarkly focuses on feature management first, with experimentation layered into the same workflows. Pricing starts at $75 per seat per month, which positions it as an enterprise solution for teams that treat feature flags as critical infrastructure.
Warehouse-Native Experimentation: Eppo and Statsig
Data-mature organizations benefit from warehouse-native A/B testing platforms that use existing analytics infrastructure. Eppo runs tests directly on data warehouses like Snowflake, BigQuery, Databricks, or Redshift using existing metric definitions. This approach removes data silos and keeps experimentation aligned with business intelligence workflows.
Statsig also supports warehouse-native architecture while offering an easier entry point through its generous free tier. Both platforms include advanced statistical methods such as sequential testing and CUPED variance reduction. Eppo focuses heavily on statistical rigor with automatic quality checks, including SRM detection, which appeals to teams with strict data standards.
Statsig vs Eppo: Matching Tools to Team Maturity
Statsig fits startups and growth-stage companies that need immediate value with minimal setup. Its free tier and developer-friendly design help teams without dedicated data infrastructure get experiments running quickly. Eppo suits data-mature organizations with strong warehouse investments and analytics teams that prioritize statistical rigor over ease of setup.
The following table summarizes how each platform’s pricing and integration approach aligns with different team maturity levels:
|
Tool |
Best For |
Pricing |
Integrations |
|
PostHog |
Startups, All-in-one |
Free to 1M events |
Self-hosted, APIs |
|
Statsig |
Growth-stage SaaS |
Free to $150/month |
Warehouse-native |
|
Eppo |
Data-mature teams |
Custom enterprise |
Snowflake, BigQuery |
|
Amplitude |
Analytics-driven |
Free to $49/month |
Amplitude ecosystem |
|
LaunchDarkly |
Feature management |
$75/seat/month |
All major SDKs |
|
GrowthBook |
Open-source |
Free to $20/user |
SQL warehouses |
|
Optimizely |
Enterprise |
$36,000+/year |
Full-stack |
Enterprise Full-Stack Platforms: Optimizely and VWO
Large organizations running hundreds of concurrent experiments need platforms with strong governance and collaboration features. Optimizely provides full-stack testing across web, server-side, and mobile with a powerful Bayesian statistics engine. Its feature set includes advanced targeting, personalization, and audit trails that support enterprise compliance.
VWO offers similar enterprise capabilities at a more accessible price point. Starting at $199 per month, VWO provides A/B testing, multivariate testing, and behavioral segmentation along with integrated CRO tools like heatmaps and session recordings.
Specialized Tools for Mobile Apps
Firebase A/B Testing offers a completely free tier with seamless Google ecosystem integration, which makes it ideal for mobile-first startups. For more advanced mobile experimentation, Apptimize provides visual editors and instant updates without app store resubmission, although it requires custom pricing.
Low-Traffic and AI-Driven Testing: Statsig Bayesian and SimAB
Low-traffic scenarios call for more sophisticated statistics to reach significance with smaller samples. Sequential testing and Bayesian approaches in advanced A/B tools provide faster and more accurate results, and they have become standard for handling low-traffic experiments in 2026.
Statsig’s Pulse engine combines sequential testing with Bayesian statistics, so experiments can end earlier when results are clear. This approach cuts the time-to-insight that used to slow low-traffic tests. Before running your next low-traffic test, book a Listen Labs demo to see how hypotheses get validated in under 24 hours.
Qual-at-Scale for Experiment Teams: Listen Labs (#1 Overall Recommendation)
A/B testing tools reveal which variant wins, but they do not explain why it wins. Listen Labs fills this gap by running AI-moderated interviews with participants from its 30M+ global panel and delivering qualitative insights in under 24 hours. This qual-at-scale approach uncovers emotional and motivational drivers behind user behavior that quantitative metrics miss.
Traditional user research often takes 4 to 6 weeks and costs thousands per study. Listen Labs compresses that timeline to hours while scaling to hundreds of interviews at once. The platform’s Emotional Intelligence analyzes tone, word choice, and micro-expressions to surface emotions that transcripts alone overlook. Microsoft used Listen Labs to collect global customer stories for their 50th anniversary within a day, which shows the speed and scale possible with this approach.
For product experiments, Listen Labs validates hypotheses before A/B testing, explains unexpected results, and uncovers new opportunities. The Research Agent generates slide decks, highlight reels, and statistical comparisons automatically, and it fits into existing experimentation workflows.
This speed and cost advantage becomes clear when comparing Listen Labs to traditional qualitative methods:
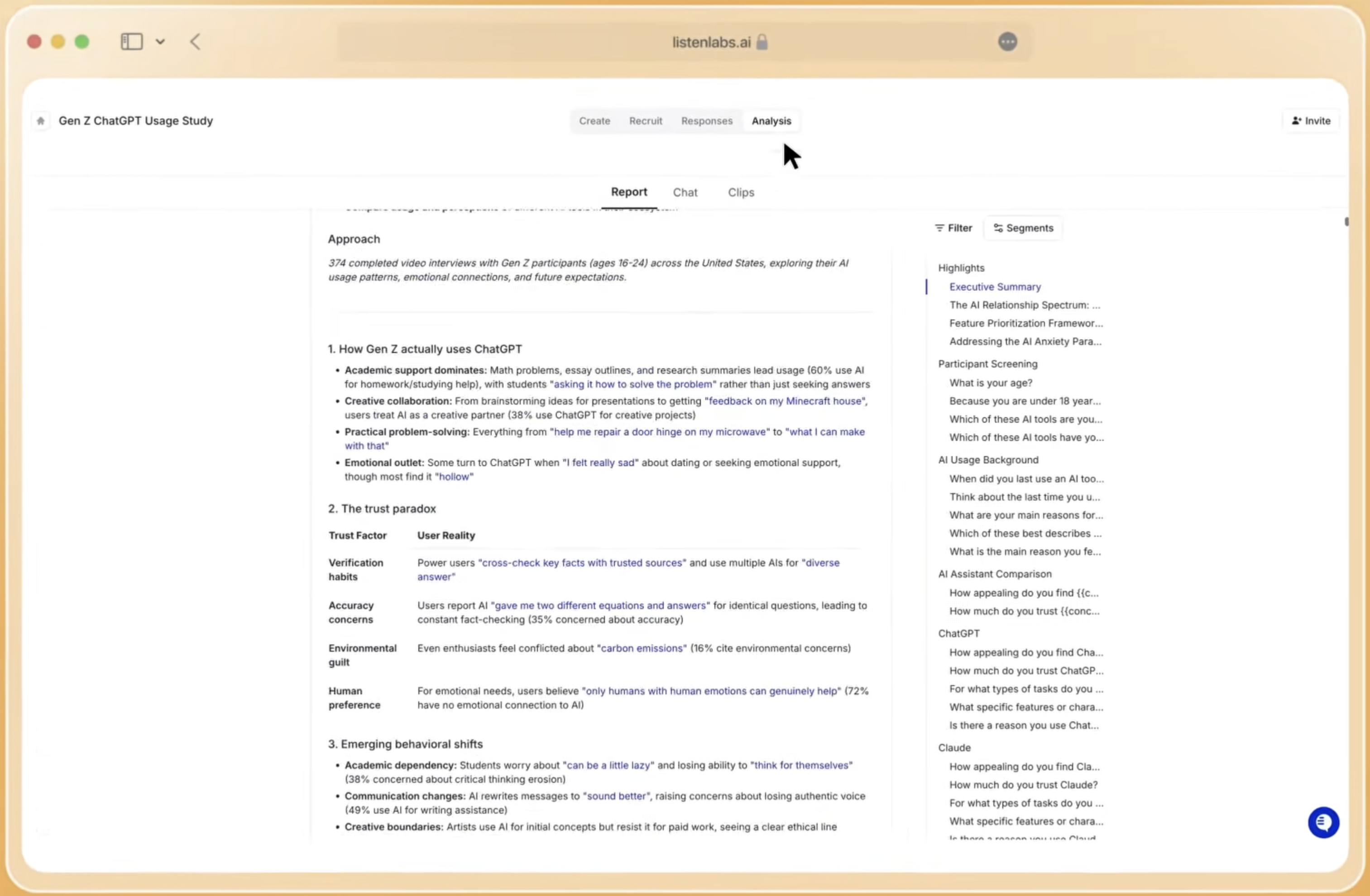
|
Method |
Time |
Cost |
Scale |
|
Listen Labs |
<24 hours |
1/3 traditional cost |
Hundreds of interviews |
|
Traditional Qual |
4-6 weeks |
High |
5-15 participants |
Start your first product experiment qual study with Listen Labs today to understand not just what your users do, but why they do it.
FAQ
What’s the difference between Statsig and Eppo for product teams?
Statsig offers a generous free tier and a developer-friendly setup, which makes it ideal for startups and growth-stage companies. Eppo focuses on statistical rigor for data-mature organizations with existing warehouse infrastructure. Choose Statsig for immediate value and accessibility, and choose Eppo for advanced statistical methods and enterprise data governance.
Which A/B testing tools are best for startups with limited budgets?
GrowthBook, PostHog, and Firebase offer the most generous free tiers. GrowthBook provides unlimited experiments with self-hosting, PostHog includes comprehensive analytics up to 1 million events monthly, and Firebase offers completely free mobile A/B testing with Google ecosystem integration.
How do I handle A/B testing with low traffic volumes?
Use tools with Bayesian statistical engines and sequential testing capabilities such as Statsig, Eppo, or GrowthBook. These approaches can detect significant results with smaller sample sizes and shorter test durations compared to traditional frequentist methods.
Do I need qualitative research after running A/B tests?
Yes, qualitative research explains the “why” behind quantitative results. A/B tests show which variation wins but not the underlying motivations. Listen Labs provides qual-at-scale insights in under 24 hours, helping teams understand user emotions, pain points, and decision-making processes that drive quantitative outcomes.
What are warehouse-native A/B testing tools?
Warehouse-native tools like Eppo, Statsig, and GrowthBook run experiments directly on existing data warehouse infrastructure such as Snowflake, BigQuery, or Redshift. This approach removes data silos, keeps metrics consistent with business intelligence, and uses existing data team definitions and governance.
Conclusion
The A/B testing landscape in 2026 offers sophisticated options for every team stage and technical requirement. Startups benefit from PostHog and Statsig’s generous free tiers, while enterprises often rely on Optimizely or VWO for advanced governance. Warehouse-native platforms like Eppo and GrowthBook serve data-mature organizations, and specialized tools like Firebase excel for mobile-first products.
The key is matching tool capabilities to your team’s maturity, traffic patterns, and integration needs. Quantitative A/B testing only tells half the story, so pair experiments with qualitative insights to understand user motivations and accelerate product decisions.
Quick picks by use case:
- Startups: PostHog or Statsig for generous free tiers
- Open-source: GrowthBook for warehouse-native testing
- Mobile-first: Firebase for free Google integration
- Enterprise: Optimizely for full-stack capabilities
- Qual validation: Listen Labs for understanding the “why”
Book a demo to add the qualitative layer your A/B tests are missing and understand not just what wins, but why.